

Taiwan & US elections forecasting WITHOUT opinion polls
Taiwan & US elections forecasting WITHOUT opinion polls
Game changer from Shiping Tang et al.?

(Enable your email to load the pictures.)
The 复旦大学复杂决策分析中心 Center for Complex Decision Analysis (CCDA), Fudan University, founded and led by Prof. 唐世平 Shiping Tang, recently reported in a peer-reviewed article on the journal Plos One of two live experiments in forecasting elections with agent-based modeling (ABM), WITHOUT opinion polls or social media data.
The two elections are the 2020 general election in Taiwan and six states in the 2020 general election in the United States.
For the Taiwan 2020 election, the error difference between the forecasted results and the actual result is less than 1%. More profoundly, the accuracy of the forecasted results based on ABM simulations greatly outperformed pre-election opinion polls and expert surveys. (see the two tables)

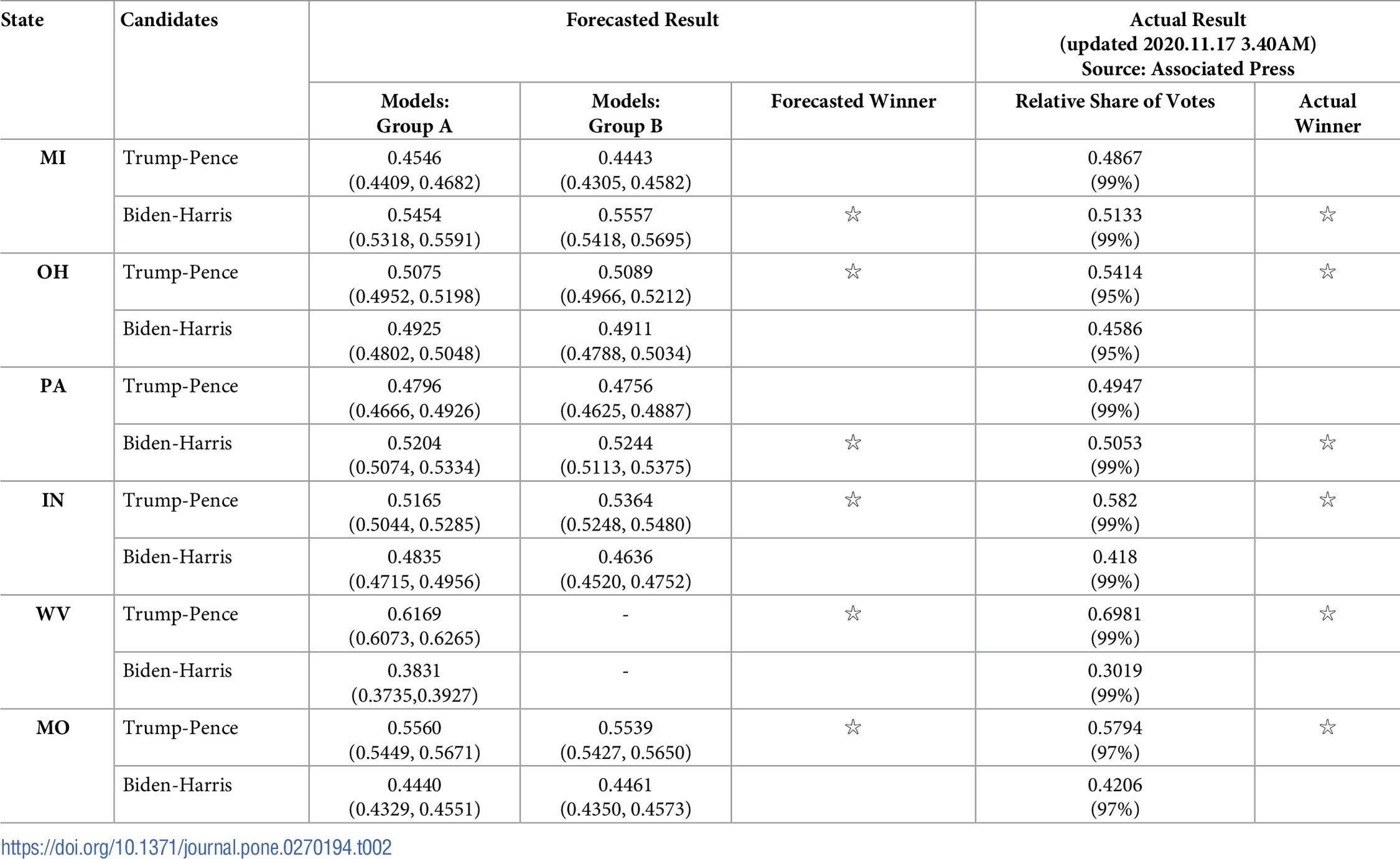
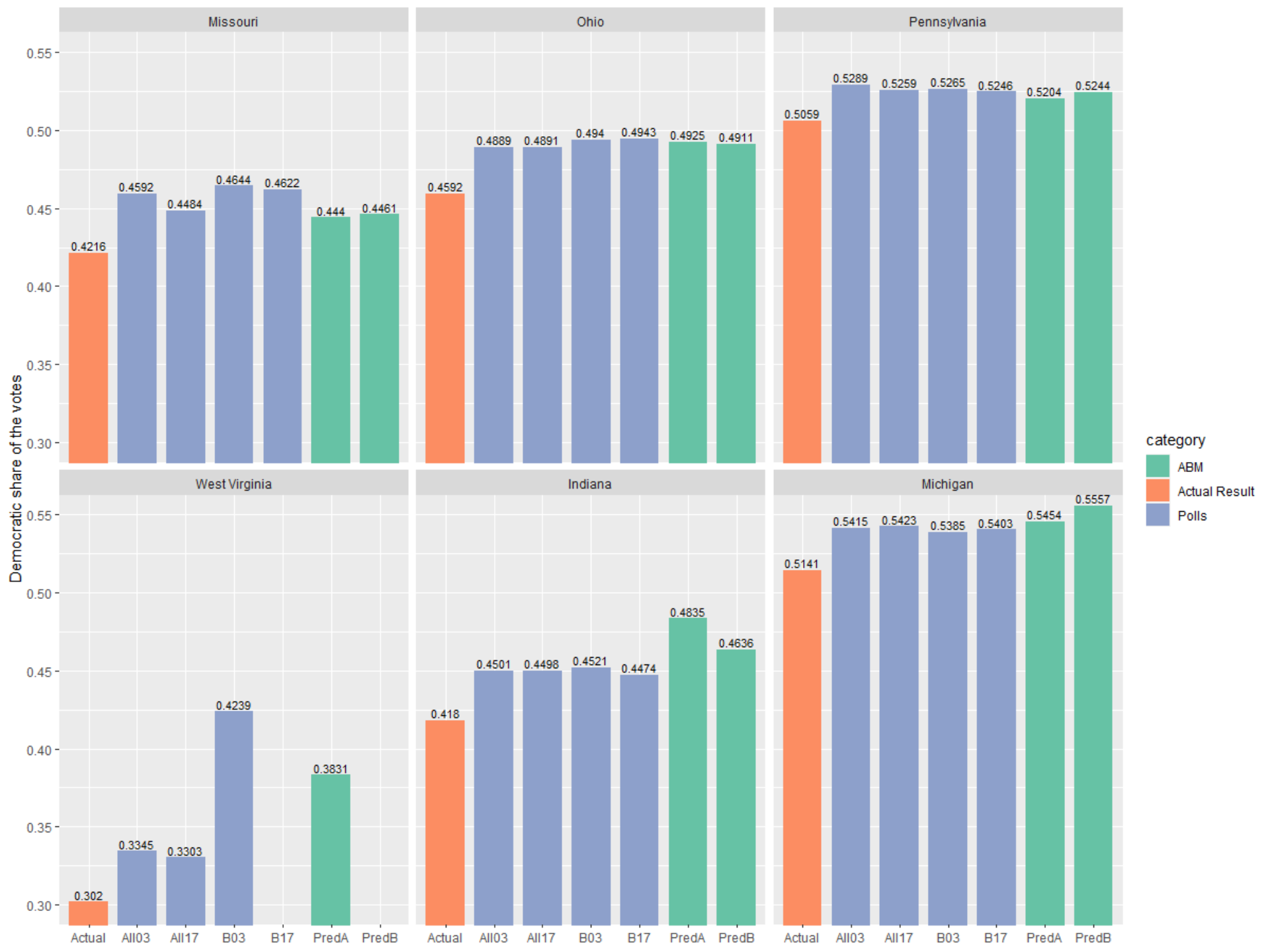
For the six states in the 2020 U.S. election, the forecasting involved Michigan, Ohio, Pennsylvania, Indiana, Virginia, and Missouri as he didn’t have funding to do more. The forecasting correctly forecasted that Trump and Pence will win in Ohio but lose in Michigan and Pennsylvania. Unfortunately, the forecasting has also over-estimated the support for Biden and Harris, as many independent or aggregated polls did. However, the forecast has been closer to the actual outcome than most polls. (see the two tables.)
The article reports that the ABM-based approach can provide the forecasting with a much longer lead time (from several months to a year), well before election polls can generate meaningful predictions (usually quite close to the election date). The approach allows for gauging how different blocs of voters are likely to vote, integrating forecasting accuracy with model interpretability and thus providing candidates and parties with a better reference point for formulating their campaign strategies and adjusting mobilization practices.
Prof. Tang has been publishing - sometimes in English - his forecasting on the website of CCDA before the elections were held - check the dates in the red box.
But now CCDA has published a peer-reviewed article, which is OPEN ACCESS!
I am simply pasting some excerpts below, but you are also welcome to head directly to the article for a thorough examination.

Citation: Gao M, Wang Z, Wang K, Liu C, Tang S (2022) Forecasting elections with agent-based modeling: Two live experiments. PLoS ONE 17(6): e0270194. https://doi.org/10.1371/journal.pone.0270194
Introduction
Election forecasting has been traditionally dominated by opinion polls, surveys, “fundamentals” and the three approaches centered upon them, namely, opinion aggregation, structuralist models, and various synthetic methods.
A major shortcoming of the above three approaches is that voters are mostly missing in forecasting exercises even though they are the key agents in determining the final outcomes. More concretely, the existing approaches do not employ much data at the level of the individual voters (e.g., gender, age, ethnicity, education, income, religion, occupation, etc.). Rather, they mainly focus on capturing how different voters will vote in response to macro-level variations or shock events. Moreover, all three approaches are keen to forecast the winner instead of the precise share of votes by different parties or candidates.
We have developed a novel platform for forecasting real-world elections that is based on agent-based modeling (ABM). To our best knowledge, we are the first to do so. Although ABM has been employed for simulating political competitions before, existing attempts have focused on establishing and identifying key dynamics in electoral competitions rather than forecasting elections in real time.
Our platform forecasts elections by systematically simulating voters’ voting behavior. As a result, we can forecast the share of votes obtained by each candidate or party rather than merely a crude outcome of an election (i.e., which side wins). Moreover, our ABM-based approach can provide the forecasting with a much longer lead time (from several months to a year), well before election polls can generate meaningful predictions (usually quite close to the election date). Finally, our approach allows for gauging how different blocs of voters are likely to vote, integrating forecasting accuracy with model interpretability and thus providing candidates and parties with a better reference point for formulating their campaign strategies and adjusting mobilization practices.
We have been experimenting with our platform for several years. In 2016, we released our first real-time forecast for the general election in Taiwan. Since then, we have released our forecasting results for the 2018 Taiwan local elections, 2018 U.S. senator elections in Missouri and West Virginia, the Taiwan 2020 general election, and the U.S. 2020 general election. All the forecasts were released publicly before the elections. Over the years, we have steadily improved our platform by 1) collecting more historical data, 2) training our models with ever-richer data and systematically testing our approach against two different electoral systems (Taiwan and the United States). Our platform has consistently performed well and often more accurately than opinion polls. In this article, we report the progress with two of our latest live experiments: the Taiwan 2020 general election and the U.S. 2020 general election.
Why ABM for electoral forecasting
ABM is a bottom-up approach for simulating the actions and interactions of agents with a specific characteristic within a system with predefined behavior rules to generate emergent outcomes at the aggregate level. Agents in ABM can be individuals, social groups, parties, governments, or any other actors of interest. Agents can be endowed with a variety of attributes, ranging from demographic characteristics to socio-economic status, that may shape their actions. An aggregate-level outcome, often stable, then emerges from repeated simulations. As a result, ABM allows researchers to simulate and analyze the macro-level phenomenon of interest from micro-level dynamics of individual behaviors.
We began to design and develop our ABM-based platform for electoral forecasting in 2015. Underpinning our project has been two key ideas. The first is that we can derive some initial voting rules of agents (voters) from historical data and then deploy ABM simulation to select (or screen) for models that can capture how different voters have voted in past elections fairly accurately by matching simulated election results with the actual results of past elections. Second, we can then deploy those selected models to forecast an upcoming election with ABM simulation by combining extrapolated individual-level data from most recent demographic record with updated structural-level data on key predictive variables such as economic growth, unemployment rate, the crime rate, and shock events, etc.
Distinctively, our platform is entirely independent from surveys and polls, which are mostly subjective and even biased. Our platform does not rely on social media data either, not simply because they are highly subjective, but also we knew, even before the Cambridge Analytics scandal during the 2016 U.S. election, that social media data can be easily manipulated and hence are often contaminated and corrupted.
Instead, our platform is underpinned by objective data and computer simulation. At the same time, we draw insights from electoral studies. Our platform not only incorporates both individual-level factors and structural-level variables but also simulates how voters have voted in past elections by taking voters as the principal agents who act upon their characteristics and respond to the structural environment. This leads to another key advantage: our platform can shed light on how different blocs of voters have voted and are likely to vote in the future.
Method
We built our platform with two starting assumptions. First, because voters are the central decision-maker in any election, they are modeled as the principal agents in our ABM simulations. Second, in addition to their individual attributes (e.g., age, gender, income, education, occupation), voters’ electoral decision is also shaped by other driving factors including macro socioeconomic factors, candidates’ attributes, and campaign dynamics. From data on all these factors and historical electoral results, we then derive some initial rules for agents’ voting behavior with simple regressions. Very critically, however, these initial rules do not have to be very accurate in the first place because ABM simulations will subsequently select models that can closely reproduce historical electoral results.
After setting agents’ attributes and these initial rules, we can then simulate how voters have voted in past elections in our platform. Models that are screened against results from past elections and found to reproduce past electoral outcomes within a small margin of error (±2.5%) are then deployed for forecasting an upcoming election in new forecasting simulations. Altogether, our election forecasting method with ABM simulation typically proceeds in five major steps

[Pekingnology: Highly technical details omitted here. Find out in the open-access paper by yourself.]
Four distinct features of our ABM forecasting platform are worth emphasizing.
First and foremost, evidently, our ABM-based forecasting does not rely on opinion polls or social media data at all. Our approach thus is distinct from the traditional forecasting techniques and more recent big-data methods.
the platform can forecast the share of votes by candidates or parties rather than merely their chance of win.
our simulations allow for deriving forecasted results several months or even a year before the real-world elections, securing a longer lead time.
if desired, our simulations help gauge how different blocs of voters with varying attributes have voted in past elections and are likely to vote in a coming election.

Two live experiments
We now explicate two live experiments we performed in 2020 to show that our election forecasting based on ABM has consistently delivered results with impressive accuracy. All forecasted results have been released online to the public at least two days before the elections, and their online links can be found in the appendixes. In fact, we have obtained our forecasted results about two months ahead of the elections. To avoid affecting the actual electoral results, however, we have deliberately released our results only two days before the elections. For the sake of space, fully detailed descriptions of these experiments are presented in the appendixes. (For our earlier forecasting efforts, which have also been fairly accurate, please visit our official website: www.ccda.fudan.edu.cn).
Experiment 1: Live forecasting of the 2020 Taiwan general election
At 10 am (Beijing time) on January 9, 2020 (two days ahead of the election date in Taiwan), we released our forecasted results for the 2020 Taiwan general election. This real-time forecasting experiment based on ABM follows the standardized forecasting procedures detailed in the previous section.
For the Taiwan election, we designed two sets of models with different input variables. The key difference between the two sets of models is that group A models contain occupation (agriculture, manufacturing, or service sector), whereas group B models replace it with religious beliefs. These two sets of models were then deployed to forecast the election respectively.
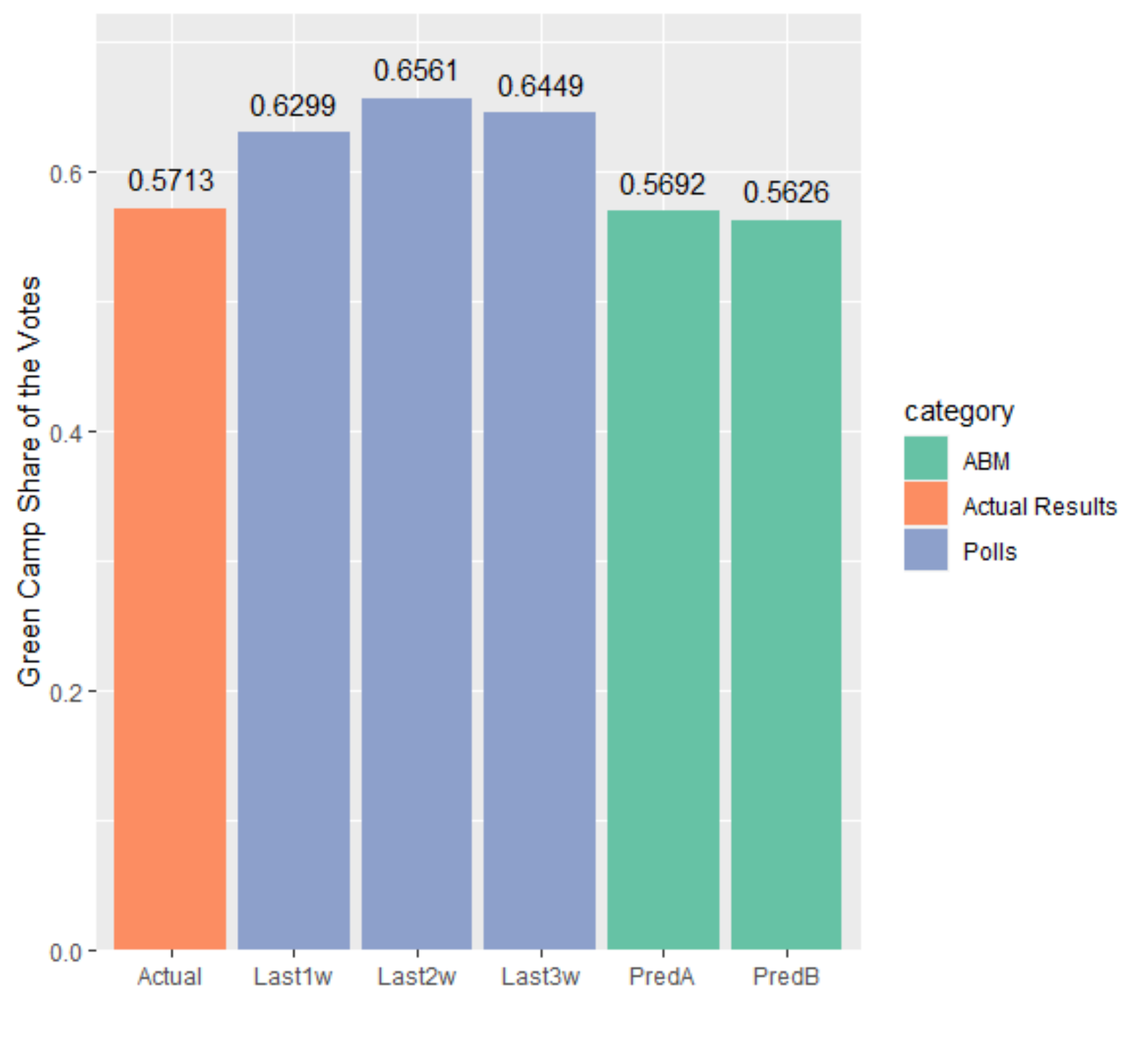
The overall results of the two sets of models turned out to be very close. More concretely, the first set of models (the group A models), with 13 individual models, predicted that the Green Camp (the incumbent, Tsai Ing-wen) will receive anywhere between 55.17% (lowest) and 59.48% (highest) of the popular vote, with the averaged share of vote being 56.92%.
The second set of models (the group B models), with 611 individual models, predicted that the Green Camp will receive anywhere between 54.06% (lowest) and 59.74% (highest) of the total vote, with the averaged share of vote being 56.26%. [Note: As we recheck the results, we discover that due to an unwarranted error of calculating the means of the results obtained by all the models, our released results (56.86% and 56.42% respectively for group A models and group B models) are slightly different from the correct calculation (56.92% and 56.26% respectively for group A models and group B models). Despite the tiny numerical differences, we sincerely apologize for our mistake.]
Our forecasted results are proven to be extremely close to the final actual election result in 2020. In the actual election, the incumbent Tsai won with 57.13% of the popular vote. In fact, the error difference between our forecasted results and the actual result is only 0.21% for group A models and 0.87% for group B models , both less than 1%. More profoundly, the accuracy of our forecasted results based on ABM simulations greatly outperformed pre-election opinion polls and expert surveys.

Experiment 2: Live forecasting of the 2020 U.S. general election
At 12 am (Beijing time) on November 1, 2020 (two days before the presidential election in the United States), we released our computer simulation-based forecasting for the relative shares of votes in the upcoming 59th US presidential election. Due to the budget limit, we can only perform ABM simulation-based forecasting for six selected states (Michigan, Ohio, Pennsylvania, Indiana, Virginia, and Missouri). [Note: In the long run, it will be desirable to be able to forecast the results for all major swing states with ABM simulation. Such an enterprise, however, requires far more resources than what we can afford now.] For these six states, our simulation has produced the forecasted results in early Sept. In fact, we simulated the election results three times, on April 23, July 05, and then finally on September 28 of 2020.
Again, we created two sets of models with different input variables. A key difference between group A models and group B models is that among the variables in our models, the former contains occupation in which sector (agriculture, manufacturing, or others) whereas the latter replaces it with ethnic background. These two sets of models were then deployed to forecast the real-world election respectively. Similar to the results generated in our simulation of the 2020 election in Taiwan, the overall forecasted results for the 2020 US presidential election obtained by the two sets of models are also very close
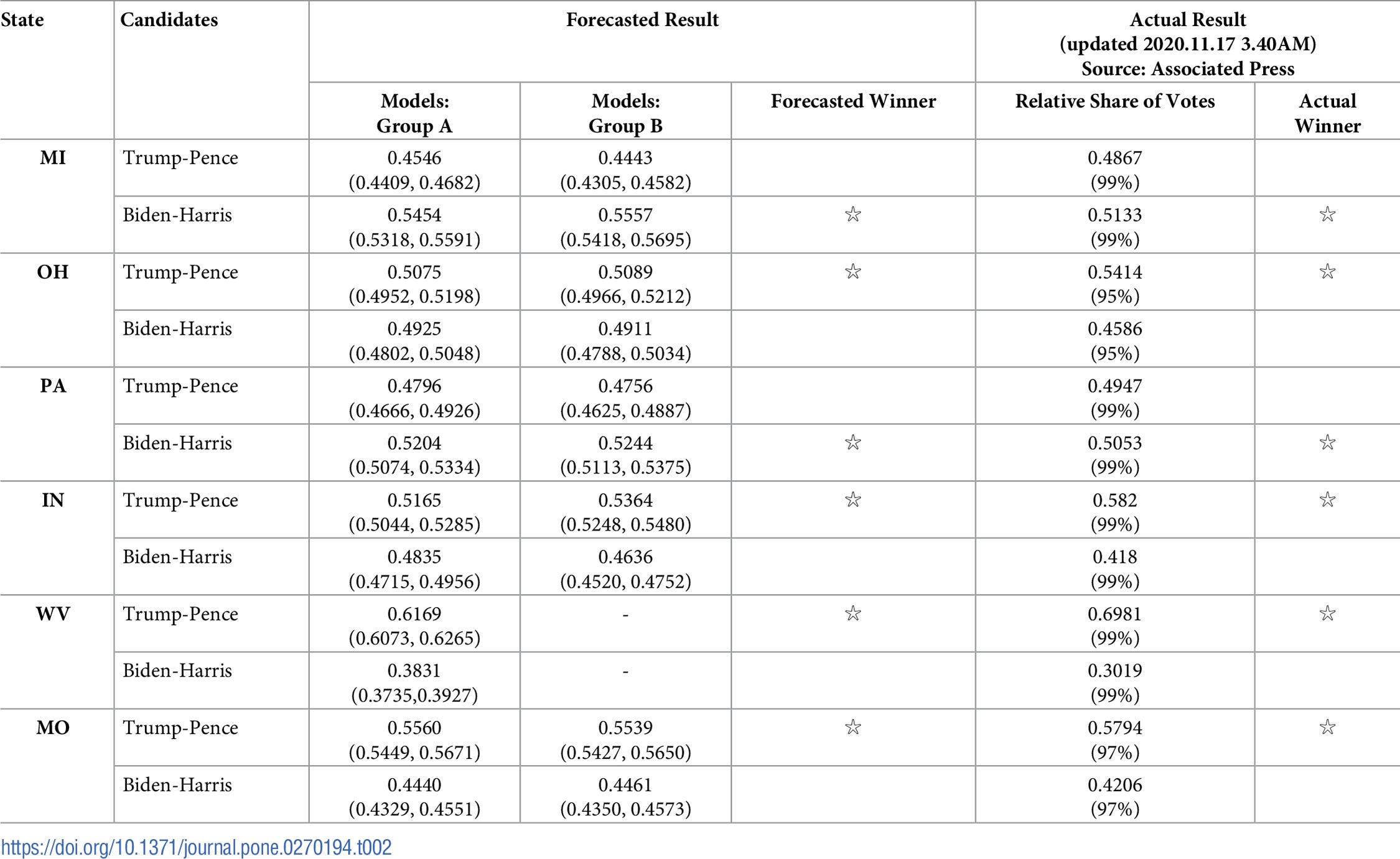
Our forecasting has correctly predicted the outcomes in all six states. In particular, we correctly forecasted that Trump and Pence will win in Ohio but lose in Michigan and Pennsylvania. Unfortunately, our forecasting has also over-estimated the support for Biden and Harris, as many independent or aggregated polls did. However, our forecast has been closer to the actual outcome than most polls. As our first attempt of forecasting the U.S. presidential election, we deem our forecasting effort using ABM to be good despite a larger margin of errors than our earlier efforts of forecasting Taiwan general elections.
Conclusion
Forecasting elections remains a challenging endeavor. Using ABM simulations, we have performed several experiments of real-time election forecasting since 2015. All of our forecasted results were preregistered and made publicly available several days ahead of the elections. Although we typically obtained our forecasts months before the actual election, we always hold these results in order to avoid being accused of affecting the real world outcome. So far, all of our forecasted results have proven to be fairly accurate when compared to the eventual outcome of these elections. Moreover, our forecasted results obtained several months before the election day have consistently performed better than most polls back then. Our experiments therefore point to ABM as a powerful, perhaps even revolutionary, tool for forecasting elections. Compared with traditional forecasting methods, the agent-based simulation approach boasts several remarkable advantages.
our ABM platform operates on objective data and uses computational modeling instead of relying on opinion surveys, expert judgments, and fragmented news information.
our ABM platform brings together micro-level and macro-level predictive variables.
Voters are brought back in as principal decision-making agents in the forecasting process, making our forecasting much closer to the real voting process than opinion aggregations and regression models. election forecasting based on ABM is grounded in well-established electoral studies in political science. Variable selection, data collection, and model construction for the ABM forecasting are closely guided by electoral theories in political science, a process where political scientists work in close collaboration with computer scientists. Doing so generates more accurate results and provides deeper insights into the explanation of the outcomes of interest.
closely related to the third, forecasting and explanation mutually benefit each other. Electoral forecasting based on ABM simulations rests on robust political science theories, has higher analytic tractability, and enhances our cumulative knowledge about how elections work in different settings. In particular, our ABM platform allows us to use predictive factors varying depending on electoral circumstances.
Overall, the novel forecasting approach of ABM simulations enables us to make forecasts on an earlier date with high predictive accuracy and more explanatory power, which shows the most promise for future election forecasting.
Looking ahead, we see several directions for further exploration.
various machine learning tools can potentially aid the selection of models and equations in the second and third rounds of model screening.
forecasting multi-party elections under more complex electoral landscapes is certainly far much challenging, and it will be extremely interesting to test whether ABM-based platform can perform equally well in such settings.
Overall, we are confident that through continuous improvement, our ABM-based platform can potentially bring transformational change to election forecasting.
Citation: Gao M, Wang Z, Wang K, Liu C, Tang S (2022) Forecasting elections with agent-based modeling: Two live experiments. PLoS ONE 17(6): e0270194. https://doi.org/10.1371/journal.pone.0270194
For two other pieces of work EXCLUSIVE in English to Pekingnology by Prof. Shiping Tang
